
-
Start
-
Exchange Server
-
Exchange Hybrid
-
Exchange Online
-
- Artikel in Kürze
-
- Artikel in Kürze
-
- Artikel in Kürze
-
Managed Availability: Wie Exchange sich selbst heilt
Dieser Artikel erklärt, was Managed Availability in Exchange Server ist, wie die internen Komponenten zusammenarbeiten und welche Voraussetzungen erfüllt sein müssen, damit die automatische Selbstheilung zuverlässig funktioniert.
Voraussetzungen
Managed Availability ist ab Exchange Server 2013 verfügbar und in allen weiteren Versionen (2016, 2019, SE) integriert. Für die vollständige Funktionsfähigkeit der automatischen Korrekturmechanismen wird eine Datenbankverfügbarkeitsgruppe (DAG) mit mehreren Servern benötigt. In einer Einzelserver-Installation sind zwar die Probes und Monitore aktiv, Responder-Aktionen wie ein Datenbank-Failover lassen sich jedoch nicht ausführen. Die Exchange Preferred Architecture sollte als Implementierungsgrundlage dienen.
Funktionsweise
Überblick
Managed Availability ist eine Kernkomponente der Exchange-Hochverfügbarkeitsfunktionen. Es fungiert als internes Überwachungssystem, das kontinuierlich Verbindungsendpunkte, Antwortzeiten und die Funktionalität einzelner Exchange-Komponenten überwacht. Das Ziel ist, den Systemstatus automatisch und schnell auf einen optimalen Betriebszustand zurückzuführen, ohne dass manuelle Eingriffe erforderlich sind.
Für die Funktionstests nutzt Exchange Server spezielle Health Mailboxen, um Protokoll- und Funktionstests durchzuführen. Jedes Postfachdatenbank verfügt über eigene, von Exchange verwaltete Health Mailboxen. Dabei werden neben den internen Exchange-Endpunkten (z.B. OWA, ActiveSync, EWS) auch externe Komponenten wie Domain Controller und DNS-Server überprüft.
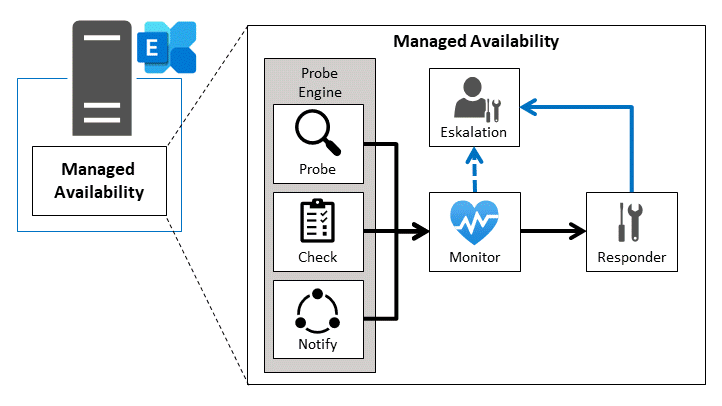
Kernkomponenten
Die Managed Availability besteht aus drei zentralen Komponenten:
- Probe Engine
Führt Messungen und Funktionstests regelmäßig in festgelegten Intervallen durch. Ein Exchange Server nutzt Hunderte von Probes, um Erreichbarkeit, Latenz und Funktionalität zu überprüfen. Den aktuellen Status der Probes kann man über die Health-Cmdlets abfragen. - Monitor
Analyisiert die Daten, die von den Probes gesammelt werden. Hier ist die Business-Logik implementiert, die bestimmt, ob ein Zustand als problematisch gilt. - Responder
Bestimmt, welche Maßnahme bei einem erkannten Problem ergriffen wird, entweder eine Eskalation an Administratoren (durch einen Ereignislogeintrag) oder eine direkte automatische Korrektur. Der Exchange Health Manager Service überwacht und steuert den Health Manager Worker-Prozess, um sicherzustellen, dass ein Fehler im Worker-Prozess nicht zum vollständigen Ausfall der Managed Availability führt.
Responder-Aktionen am Beispiel OWA
Die Responder-Aktionen folgen einer Eskalationslogik mit mehreren Stufen. Erkennt die Probe-Engine ein Problem mit Outlook on the Web, läuft die Reaktionskette wie folgt ab.
- Neustart des OWA-Applikationspools
- Neustart des W3SVC-Dienstes
- Neustart des Servers (als harter Neustart per Bug-Check, kein regulärer Shutdown)
Ein unerwartet heruntergefahrener Exchange Server ist häufig auf eine Managed Availability-Responder-Aktion zurückzuführen.
Prüfung
Den aktuellen Gesundheitszustand eines Exchange Servers und seiner Komponenten lässt sich mit den Health-Cmdlets abfragen.
# Gesamtstatus aller Health Sets eines Servers abfragen
# Liste enthält ca. 1667 Health Sets
Get-ServerHealth -Identity <ServerName> | Sort-Object AlertValue
# Unhealty Health Sets anzeigen
Get-HealthReport -Identity <ServerName> | Where-Object {$_.AlertValue -ne "Healthy"}
Für eine genauere Analyse, besonders nach unerwarteten Neustarts, empfiehlt es sich, die Crimson Channel-Ereignisprotokolle zu überprüfen. Diese sind in der Ereignisanzeige unter
Microsoft > Exchange > ManagedAvailability.
Bekannte Probleme und Hinweise
Unerwartete Server-Neustarts: Meldet Windows beim RDP-Login, dass der letzte Shutdown unerwartet durchgeführt wurde, sollten zuerst die Crimson Channel-Ereignislogs auf Managed Availability-Einträge geprüft werden, bevor andere Ursachen untersucht werden.
Administrator-Eskalation ist kein Alert: Eine Eskalation durch die Managed Availability bedeutet lediglich einen Ereignislogeintrag. Eine automatische Benachrichtigung der Administratoren erfolgt nicht. Ohne ein externes Monitoring-Tool (z.B. über SCOM oder ein Exchange-spezifisches Monitoring-Produkt) gehen diese Einträge im Betrieb unter.
Managed Availability Overrides: Für bestimmte Probes lässt sich das Verhalten der Managed Availability anpassen. Lokale Overrides gelten nur für den jeweiligen Server, globale Overrides wirken sich auf die gesamte Exchange-Organisation aus. Overrides sollten mit Bedacht eingesetzt werden, da sie das automatische Selbstheilungsverhalten einschränken können.
Einzelserverinstallation: In einer Umgebung ohne DAG kann die Managed Availability zwar Probleme erkennen und Dienste neu starten, ein Datenbank-Failover auf einen anderen Server ist aber nicht möglich. Der volle Nutzen der automatischen Korrekturmechanismen steht nur in einer DAG-Umgebung zur Verfügung.